The sniff
I was working in VS Code when it updated itself, as it does.
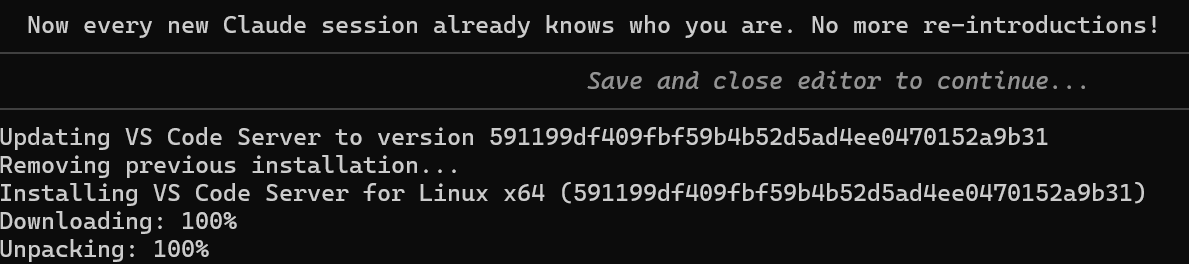
The commit hash 591199df409fbf59b4b52d5ad4ee0470152a9b31 caught my eye. I Googled it out of idle curiosity, expecting the VS Code GitHub release page. Instead I got this:
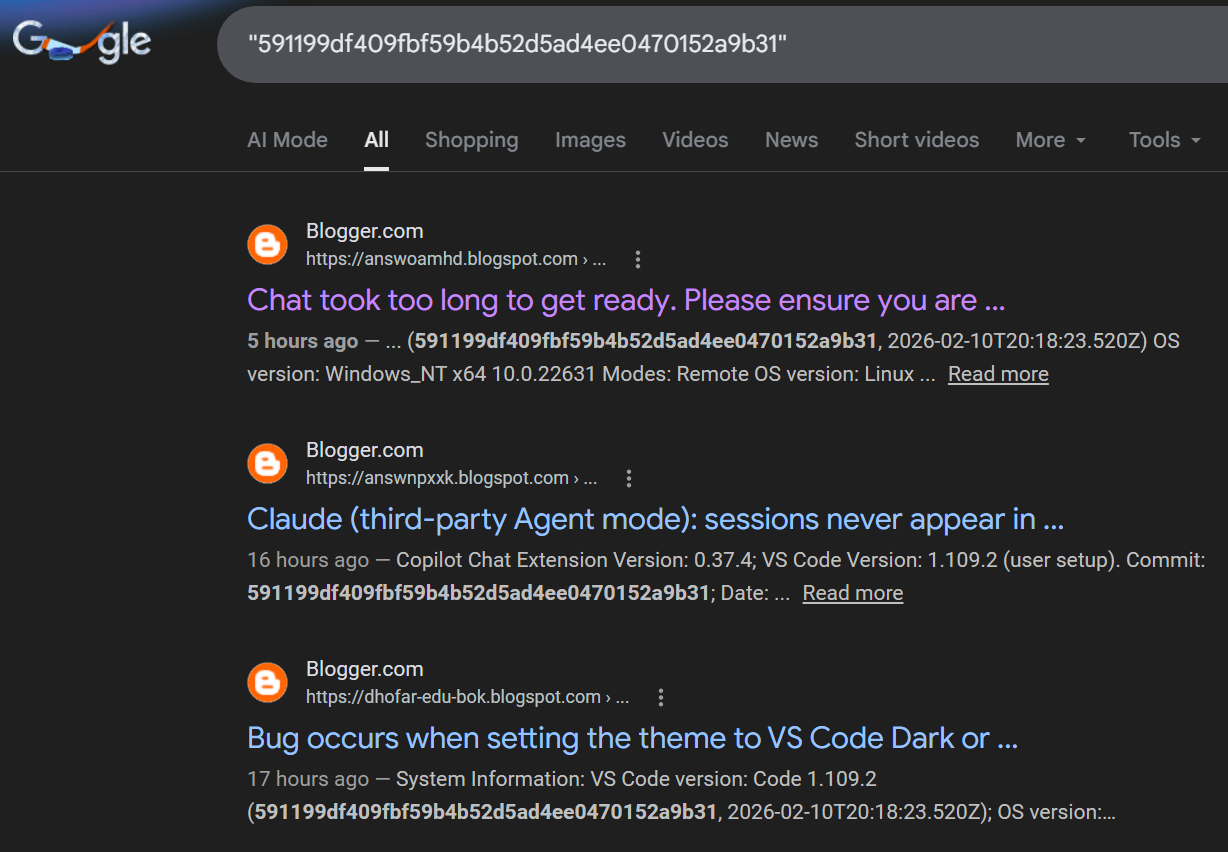
Every result is a Blogger site with a random subdomain: answoamhd.blogspot.com, answnpxxk.blogspot.com, dhofar-edu-bok.blogspot.com, assktkrlbh.blogspot.com, etc. The snippets definitely look like GitHub Issues but the domains are all wrong, and clicking through to any of these sites gives you this instead:

Akses Ditolak Maaf, Anda tidak di izinkan untuk menampilkan kontent CSR di website ini. Hal ini mungkin terjadi karena:
Anda belum menambahkan domain website ini ke akun Anda. jika anda belum memiliki akun, silahkan daftar terlebih dahulu. Kemudian tambahkan domain website ini ke bagian Add Domain di dashboard Anda. Anda telah memiliki akun, tetapi anda belum menambahkan domain website ini ke akun Anda. silahkan tambahkan domain website ini ke bagian Add Domain di dashboard Anda. Login ke panel dashboard daftar akun Butuh bantuan? Hubungi Developer (admin)
Access Denied Sorry, you are not allowed to display CSR content on this website. This may be because:
You have not added this website domain to your account. If you don’t have an account, please register first. Then add this website domain to the Add Domain section of your dashboard. You already have an account, but you haven’t added this website domain to your account. Please add this website domain to the Add Domain section of your dashboard. Log in to your dashboard panel Register an account Need help? Contact the Developer (admin)
Looks like a petty cybercrime in progress… What is it?
Mechanism
It turns out to be even more clumsy than I expected. The scheme works as follows:
- A bot scrapes GitHub Issues in bulk — bug reports, feature requests, anything with searchable technical strings like commit hashes and error messages.
- The scraped content is published across hundreds of programmatically generated Blogger sites. The random subdomain names (
answoamhd,answnpxxk,assktkrlbh) are the telltale sign of automated creation. - The sites are cloaked. They serve different content depending on who visits. Googlebot sees the scraped GitHub text (so it gets indexed and ranked). Human visitors see the “Akses Ditolak” page, or get redirected to ads, phishing, or malware.
- The Indonesian language of the error page and the mention of “CSR” (Client-Side Rendering) content suggests this is a specific cloaking-as-a-service (CaaS) platform, likely Indonesian-operated, that the spammer is using as middleware – incompetently. Imagine trying to SEO for a few dollars, but failing to even set up the CaaS, and all they accomplished was advertisement for the CaaS, rather than whatever they were trying to do.
Okay, what were they trying to do? SEO parasitism on long-tail queries. Basically, developers routinely Google exact commit hashes, error messages, and version strings. By republishing content containing these strings, the spam network hijacks that search traffic. The target could be ad revenue, malware distribution, or building backlink authority to sell later.
Why Blogger specifically? It’s owned by Google, so blogspot.com domains inherit baseline domain trust in Google’s search rankings. Free hosting, high domain authority, slow moderation, making it a well-used abuse vector.
Where did it come from?
I traced one of the search results back to its source. The search engine snippet:
Claude (third-party Agent mode): sessions never appear in ...
Blogger.com
https://nairobi-edu-betz.blogspot.com/?page=en-git-microsoft-vscode-1770791872321
17 hours ago — Commit: 591199df409fbf59b4b52d5ad4ee0470152a9b31; Date: 2026-02-10T20:18:23.520Z; Electron: 39.3.0; ElectronBuildId: 13168319; Chromium: 142.0 ...Read morematched microsoft/vscode#294443, a GitHub Issue opened 17 hours ago! So the scraping pipeline is fast. Issues are being republished to Blogger within the hour.
As for the “admin” behind the admin interface, it points to this rather grindset Facebook group AGC CSR that is dedicated to … AGC (Automatic Generated Content) and CSR (Client-Side Rendering).
Report, Retry, Fail?
So I tried reporting it. And since manual reporting is too boring, I asked Claude Opus 4.6 to find an API for auto-reporting.
1th attempt
Google has a spam report form, but it’s just a manual web form behind a Google login, and it proudly states “Google does not use these reports to take direct action against violations”. What a fancy implementation of 2>/dev/null over HTTPS.
2th attempt
The Web Risk Submission API exists, but it’s for phishing and malware only, and requires contacting Google sales for access. There is no API for reporting search spam.
3th attempt
Since these are Blogger sites hosted by Google, the more direct route should be Blogger’s own abuse reporting.
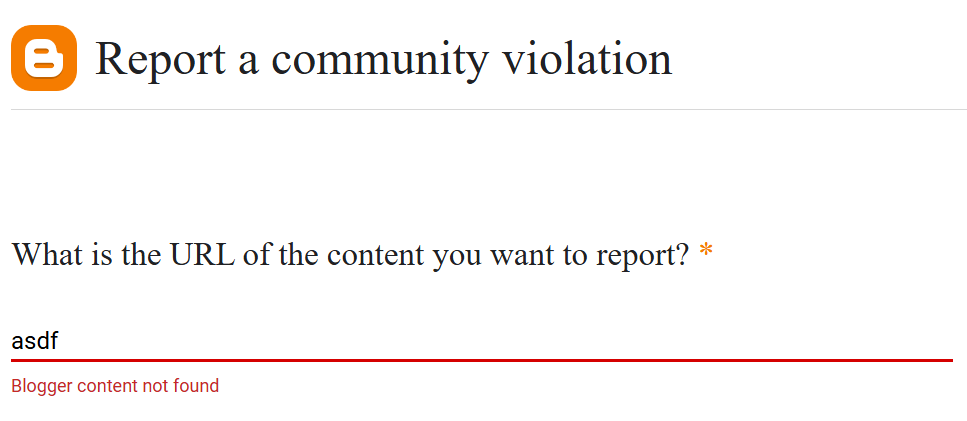
Its code is an unreadable mess in the JavaScript SPA style:
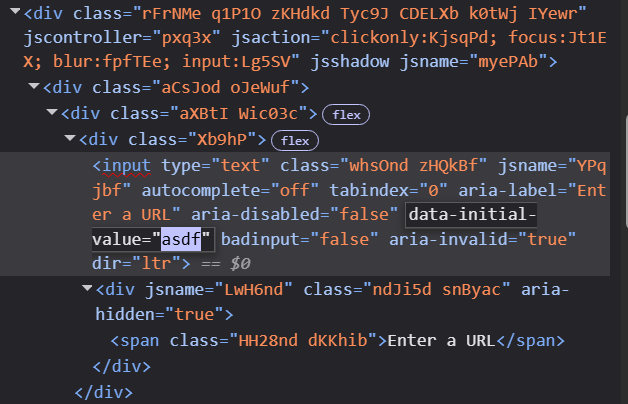
<div class="Xb9hP">
<input type="text" class="whsOnd zHQkBf" jsname="YPqjbf"
autocomplete="off" tabindex="0" aria-label="Enter a URL"
aria-disabled="false" data-initial-value="" badinput="false"
aria-invalid="false">
</div>No <form action="..."> or visible POST endpoint. Everything goes through opaque RPC calls with serialized payloads. The class names (Xb9hP, whsOnd, zHQkBf) are minified at build time and change between deployments. Editing the form would make the class names change unpredictably as you type, making automation even harder. Technically, I could reverse-engineer the submission flow, but I’m not paid enough for this, and in any case, it would break the next time Google deploys.
Basically
| Approach | Result |
|---|---|
| Google spam report form | Manual web form, no API, reports are “suggestions” |
| Web Risk Submission API | Phishing/malware only, requires sales contact |
| Blogger abuse form | JS SPA, not scriptable |
| Safe Browsing report | Phishing only, not SEO spam |
Google will catch up eventually (I just refreshed the search and only 1 of these spam URLs still remain), but still, this shows a deeper, economic problem. The problem of asymmetry… Google has made it trivially easy for spammers to create hundreds of Blogger sites programmatically (the Blogger API is well-documented and free), but has made it nearly impossible to report them programmatically.
What if we go in the opposite direction? Make creation manual and reporting automatic? That… probably isn’t good either. It might be like YouTube. Creating content is manual, but popular creators would be spammed with automated abuse reports, not to mention automated copyright reports. Sometimes these abuse reports slide through the cracks, and making the appeal is another exercise in futility.